
sha1算法
sha1算法又名哈希算法
简介
SHA-1(Secure Hash Algorithm 1)是一种密码散列函数,美国国家安全局设计,并由美国国家标准技术研究所(NIST)发布为联邦资料处理标准(FIPS)。SHA-1可以生成一个被称为消息摘要的160位(20字节)散列值,散列值通常的呈现形式为40个十六进制数。
实现步骤
消息填充(Message Padding)
步骤一: 数据填充(Append Padding Bits)
SHA-1是按照分块进行处理的,分块长度为512bit, 大多数情况下,数据的长度不会恰好满足是512的整数倍,因此需要进行「padding」到给定的长度。
「填充规则」: 原始明文消息的b位之后补100…, 直到满足b + paddingLength % 512 = 448, 那如果b % 512在[448, 512(0)]之间呢,则在增加一个分块,按照前面的规则填充即可。
长度填充
之前说了,需要满足b + paddingLength % 512 = 448, 那么对于最后一个分块,就还剩512 - 448 = 64 bit 这剩下的64bit存放的是原始消息的长度,也就是b。「SHA-1」最多可以处理明文长度小于等于2^64 bit的数据。
计算摘要(Computing the Message Digest)
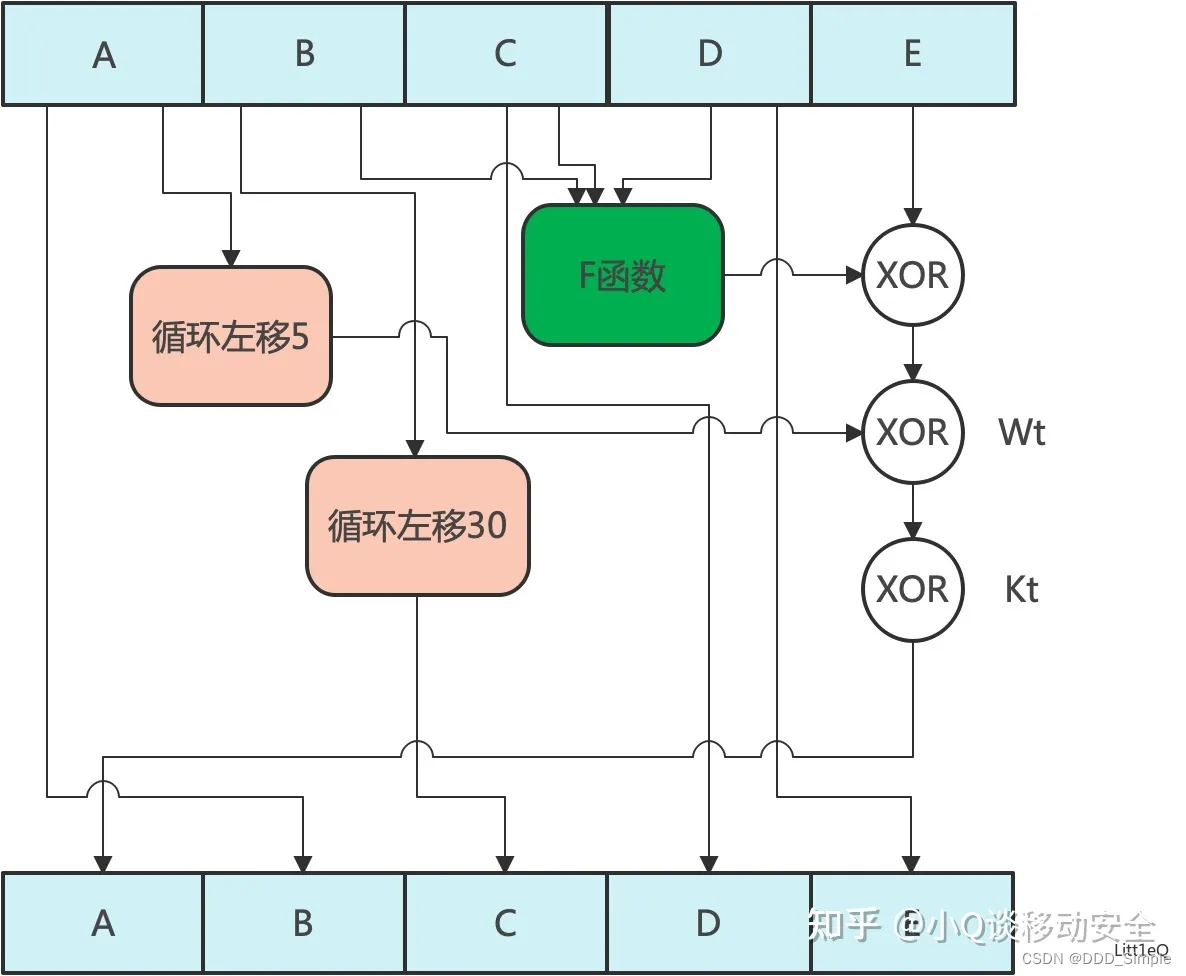
首先, 初始化5个常量, 如下所示, 类比于「MD5」可以看做是「MDBuffer」:
H0 = 0x67452301
H1 = 0xEFCDAB89
H2 = 0x98BADCFE
H3 = 0x10325476
H4 = 0xC3D2E1F0
然后对于消息按照如下的方式进行处理:
- 前16个字节([0, 15]),转换成32位无符号整数。
- 对于后面的字节([16, 79])按照下面的公式进行处理
W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16))
- 令A = H0, B = H1, C = H2, D = H3, E = H4
- 做如下80轮的散列操作
TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
E = D;
D = C;
C = S^30(B);
B = A;
A = TEMP;
- 令H0 = H0 + A, H1 = H1 + B, H2 = H2 + C, H3 = H3 + D, H4 = H4 + E
解释一下,其中f函数如下:
f(t;B,C,D) = (B AND C) OR ((NOT B) AND D) ( 0 <= t <= 19)
f(t;B,C,D) = B XOR C XOR D (20 <= t <= 39)
f(t;B,C,D) = (B AND C) OR (B AND D) OR (C AND D) (40 <= t <= 59)
f(t;B,C,D) = B XOR C XOR D (60 <= t <= 79)
k函数如下:
K(t) = 0x5A827999 ( 0 <= t <= 19)
K(t) = 0x6ED9EBA1 (20 <= t <= 39)
K(t) = 0x8F1BBCDC (40 <= t <= 59)
K(t) = 0xCA62C1D6 (60 <= t <= 79)
输出
最后H0~H4即为最终「SHA-1」的输出结果。
代码实现
pub struct SHA1 {}
impl SHA1 {
fn padding(message: &[u8]) -> Vec<u8> {
let mut result = message.to_owned();
// padding 1
result.push(0x80);
// padding 0
while ((result.len() * 8) + 64) % 512 != 0 {
result.push(0b00000000);
}
// padding message length 注意这里和MD5不同,没仔细看踩了一个大坑 这里长度padding到前面
for byte in &((message.len() * 8) as u64).to_be_bytes() {
result.push(*byte);
}
return result;
}
fn k(t: usize) -> u32 {
match t {
n if n < 20 => 0x5A827999,
n if 20 <= n && n < 40 => 0x6ED9EBA1,
n if 40 <= n && n < 60 => 0x8F1BBCDC,
n if 60 <= n && n < 80 => 0xCA62C1D6,
_ => 0,
}
}
fn f(t: usize, b: u32, c: u32, d: u32) -> u32 {
match t {
n if n < 20 => (b & c) | ((!b) & d),
n if 20 <= n && n < 40 => b ^ c ^ d,
n if 40 <= n && n < 60 => (b & c) | (b & d) | (c & d),
n if 60 <= n && n < 80 => b ^ c ^ d,
_ => 0,
}
}
pub fn hash(message: &[u8]) -> String {
let padding_message = SHA1::padding(message);
let mut buf: [u32; 5]; // Buffer one, A..E
let mut h: [u32; 5] = [0x67452301, 0xEFCDAB89, 0x98BADCFE, 0x10325476, 0xC3D2E1F0];
let mut w = [0u32; 80]; // Sequance of W(0)..W(79)
let mut temp: u32;
for chunk in padding_message.chunks(64) {
// 注意这里用的是big-edition
let m: Vec<u32> = chunk.chunks(4).map(|i| {
((i[0] as u32) << 24) | ((i[1] as u32) << 16) | ((i[2] as u32) << 8) | ((i[3] as u32) << 0)
}).collect();
for i in 0..16 {
w[i] = m[i];
}
for t in 16..80 {
// W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)).
w[t] = (w[t - 3] ^ w[t - 8] ^ w[t - 14] ^ w[t - 16]).rotate_left(1);
}
buf = h;
for t in 0..80 {
// TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
temp = buf[0].rotate_left(5).wrapping_add(
SHA1::f(t, buf[1], buf[2], buf[3])
.wrapping_add(buf[4].wrapping_add(w[t].wrapping_add(SHA1::k(t)))),
);
buf[4] = buf[3]; // E = D
buf[3] = buf[2]; // D = C
buf[2] = buf[1].rotate_left(30); // C = S^30(B)
buf[1] = buf[0]; // B = A
buf[0] = temp; // A = TEMP
}
for i in 0..5 {
h[i] = h[i].wrapping_add(buf[i]);
}
}
// output
return String::from(format!(
"{:08x}{:08x}{:08x}{:08x}{:08x}",
h[0], h[1], h[2], h[3], h[4]
));
}
}
#[cfg(test)]
mod test {
use crate::sha1::SHA1;
#[test]
fn test() {
println!("sha1([empty string]) = {}", SHA1::hash("".as_bytes()));
println!("sha1([The quick brown fox jumps over the lazy dog]) = {}", SHA1::hash("The quick brown fox jumps over the lazy dog".as_bytes()));
}
}